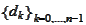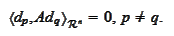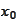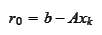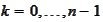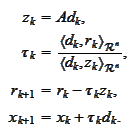he formula
(
Orthogonality of residues
) shows
the steepest descent method sometimes takes steps in the same direction that
was taken before. This is a waste of efficiency. We would like to find a
procedure that never takes the same direction. Instead of search directions
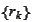 we would like to find a set of linearly independent search directions
we would like to find a set of linearly independent search directions
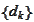 .
Of course, if the directions
.
Of course, if the directions
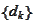 are chosen badly then the best length of step in every direction would be
impossible to determine. Since we are minimizing
are chosen badly then the best length of step in every direction would be
impossible to determine. Since we are minimizing
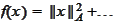 it makes sense to choose directions
it makes sense to choose directions
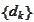 orthogonal with respect to the scalar product
orthogonal with respect to the scalar product
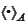 .
This way we can perform a
.
This way we can perform a
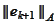 -minimization
in every direction
-minimization
in every direction
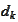 (see the section (
Method of
steepest descent
)) and guarantee that the iteration
(see the section (
Method of
steepest descent
)) and guarantee that the iteration
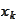 remains
remains
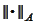 -optimal
with respect to the directions
-optimal
with respect to the directions
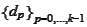 of the previous steps. Therefore such procedure has to hit the solution after
of the previous steps. Therefore such procedure has to hit the solution after
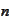 steps or less (under theoretical assumption that numerical errors are absent).
steps or less (under theoretical assumption that numerical errors are absent).
We produce a set search direction
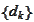 by performing the Gram-Schmidt orthogonalization (see the section
(
Gram-Schmidt
orthogonalization
)) with respect to the scalar product
by performing the Gram-Schmidt orthogonalization (see the section
(
Gram-Schmidt
orthogonalization
)) with respect to the scalar product
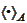 and starting from any set of linearly independent vectors. Let
and starting from any set of linearly independent vectors. Let
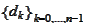 be a result of such
orthogonalization:
be a result of such
orthogonalization:
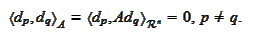 The following calculations are motivationally similar to the calculations of
the section (
Method of steepest
descent
). We start from any point
The following calculations are motivationally similar to the calculations of
the section (
Method of steepest
descent
). We start from any point
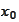 .
At a step
.
At a step
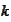 we look at the
line
we look at the
line
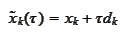 and
seek
and
seek
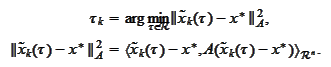 Note at this point that changing from
Note at this point that changing from
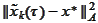 to
to
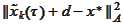 for any vector
for any vector
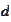 that is
that is
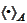 -orthogonal
to
-orthogonal
to
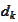 would not alter the result of minimization. Hence, if we perform this
procedure
would not alter the result of minimization. Hence, if we perform this
procedure
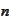 times we arrive to a point that is optimal with respect to every vector
times we arrive to a point that is optimal with respect to every vector
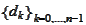 .
Therefore, such point is a solution.
.
Therefore, such point is a solution.
To perform the minimization we calculate the
derivative
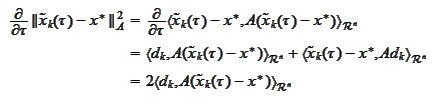 At this point we substitute the formula
(
Connection between SLA
and minimization
) and
At this point we substitute the formula
(
Connection between SLA
and minimization
) and
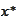 disappears from the
calculation.
disappears from the
calculation.
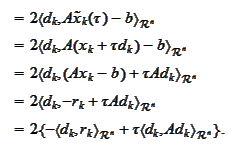 We equate the derivative to zero and
obtain
We equate the derivative to zero and
obtain
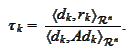 We collect the
results:
We collect the
results:
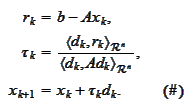 Similarly to the section
(
Method of steepest
descent
) one can eliminate one matrix multiplication by transforming the
equation
Similarly to the section
(
Method of steepest
descent
) one can eliminate one matrix multiplication by transforming the
equation
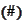 .
We multiply by
.
We multiply by
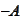 and subtract
and subtract
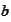 :
:
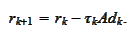
Note for future use
that
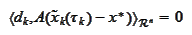 means
means
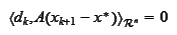 or
or
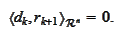 In fact,
In fact,
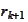 is orthogonal to all directions
is orthogonal to all directions
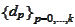 for previous steps because, as we noted already,
for previous steps because, as we noted already,
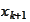 remains
remains
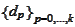 -optimal:
-optimal:
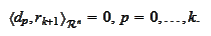
|
|
(Orthogonality of residues 2)
|
|