onsider the following example situation (see
the figure (
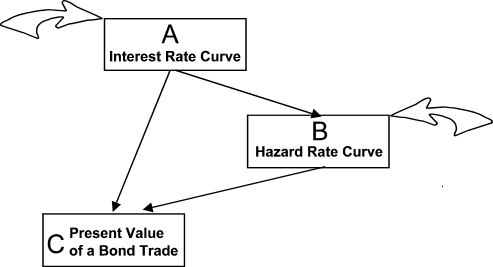
Example situation
)).
|
Example situation
|
We would like to broadcast present value of a bond trade under intense inflow
of market information. The present value depends on the "(A) Interest Rate
Curve" object and "(B) Hazard Rate Curve" object. The (A) and (B) receive
market information and become out-of-date after receiving every piece of data.
In addition, (B) is dependent on (A), hence, if (A) becomes out-of-date then
so does (B). Bringing (A) or (B) up to date is a relatively lengthy
quantitative operation. While (B) is being updated, the (A) may become
out-of-date. Therefore, if we postpone processing of (C) until both (A) and
(B) are brought up-to-date then (C) might never get any processing time.
If the CPU is slow or the flow of market data is too intense then reaching
perfect sync with the market is not possible. We could, however, reach a sync
with a state of the market as it was a small while ago. To do so we need to
schedule the processing in optimal way. We need to keep track of incoming data
to determine which object needs processing and which does not need it. We need
to keep track of dependencies between objects. These are the tasks performed
by the ots::scheduler module presented in this section.
The ots::scheduler has the following properties:
1. The delay in processing is the same for every node in the dependency tree.
2. The delay increases linearly with the number of out-of-date nodes in the
tree.
3. The delay decreases linearly with increase of the CPU power.
4. The delay has a constant asymptotic behavior when the inflow of data
intensifies.
5. The ots::scheduler grabs all memory that it needs for all processing when a
new node is added. It does not need more memory if the flow of data
intensifies. It does not do heap operations unless nodes are added or removed.
6. The processing threads never wait for each other while accessing shared
data unless there is nothing else to do.
7. The scheduling tasks are performed in optimal way.
8. If boost::thread_resource_exception is thrown then the scheduler kills and
restart the offending thread and updates the entire tree under a single thread
for one cycle. Then the normal processing is resumed. The ots::scheduler
graciously handles all other exceptions.
9. The ots::scheduler assumes nothing about the client program design.
10. An object, registered with the ots::scheduler (has a corresponding node in
the ots::scheduler tree), does not get another update request until it returns
from the current request. This, in particular, means that the ots::scheduler
takes care of most multiprocessing issues in the program. It allows to write
the client code in thread-oblivious way but does not require it.
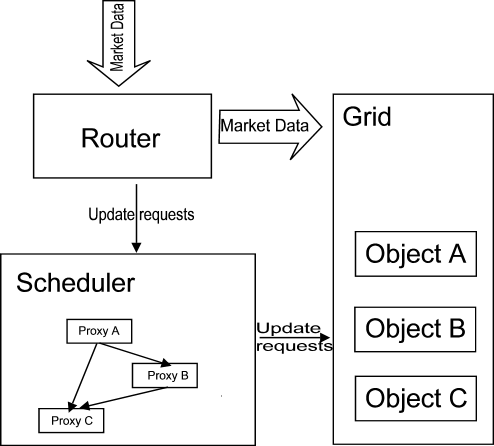
The next picture outlines a possible design with the ots::scheduler module.
|
Application design with
Scheduler
|
The business objects A,B,C,... are placed on the Grid and await an order to
update from the Scheduler. The Router redirects market information to the
objects on the Grid and notifies the Scheduler every time some object receives
a piece of market data. The Scheduler sends the "execute now" messages to the
grid.
|
